6. 모델 선택과 훈련
1. 훈련 세트에서 훈련, 평가
- 선형 회귀 모델
from sklearn.linear_model import LinearRegression
lin_reg = make_pipeline(preprocessing, LinearRegression())
lin_reg.fit(housing, housing_labels)
housing_predictions = lin_reg.predict(housing)
housing_predictions[:5].round(-2) # -2 = 십의 자리에서 반올림
>>> array([242800., 375900., 127500., 99400., 324600.])
housing_labels.iloc[:5].values
>>> array([458300., 483800., 101700., 96100., 361800.])
실제 값과 비교를 해보면 정확도가 많이 높지 않다.
RMSE를 사용하여 성능을 측정해보겠다.
from sklearn.metrics import mean_squared_error
lin_rmse = mean_squared_error(housing_labels, housing_predictions,
squared=False)
lin_rmse
>>>68687.89176589991
대부분의 중간 주택 가격은 $120,000 ~ $265,000 사이이다. 하지만 예측 오차가 $68.628인 것은 낮은 수치이다.
- DecisionTreeRegressor
결정 트리는 데이터에서 복잡한 선형 관계를 찾을 수 있다.
from sklearn.tree import DecisionTreeRegressor
tree_reg = make_pipeline(preprocessing, DecisionTreeRegressor(random_state=42))
tree_reg.fit(housing, housing_labels)housing_predictions = tree_reg.predict(housing)
tree_rmse = mean_squared_error(housing_labels, housing_predictions,
squared=False)
tree_rmse
>>> 0.0
오차가 0인 경우는 모델이 데이터에 과대적합 되었을 가능성이 높다.
모델을 론칭하기 까지는 테스트 세트를 사용하지 않기 때문에 훈련 세트의 일부분을 훈련하고 다른 일부분을 모델 검증에 사용해야 한다.
2. 교차 검증으로 평가하기
결정 트리 모델을 평가하는 훌륭한 방법에는 사이킷런의 k-폴드 교차 검증이 있다.
from sklearn.model_selection import cross_val_score
tree_rmses = -cross_val_score(tree_reg, housing, housing_labels,
scoring="neg_root_mean_squared_error", cv=10)
pd.Series(tree_rmses).describe()
>>>
count 10.000000
mean 66868.027288
std 2060.966425
min 63649.536493
25% 65338.078316
50% 66801.953094
75% 68229.934454
max 70094.778246
dtype: float64
이 코드는 훈련 세트를 폴드라 불리는 중복되지 않은 10개의 서브셋을 랜덤으로 한다.
그런 다음 결정 트리 모델을 10번 훈련하고 평가하는데, 매번 다른 폴드를 선택한다.
결과를 보면 RMSE가 66.868이고 표준 편차가 2.061이다.
결정 트리 모델이 선형 회귀 모델보다 조금 나은 것 같지만 과대적합 때문에 차이가 미미하다고 볼 수 있다.
마지막으로 RandomForestRegressor 모델을 실험해보겠다.
from sklearn.ensemble import RandomForestRegressor
forest_reg = make_pipeline(preprocessing,
RandomForestRegressor(random_state=42))
forest_rmses = -cross_val_score(forest_reg, housing, housing_labels,
scoring="neg_root_mean_squared_error", cv=10)
pd.Series(forest_rmses).describe()
>>>
count 10.000000
mean 47019.561281
std 1033.957120
min 45458.112527
25% 46464.031184
50% 46967.596354
75% 47325.694987
max 49243.765795
dtype: float64
랜덤 포레스트는 랜덤으로 선택해서 많은 결정 트리를 만들고 예측의 평균을 구하는 방식으로 작동한다.
서로 다른 모델들로 구성된 이런 모델을 앙상블이라고 한다. 앙상블은 기반 모델의 성능을 높인다.
점수를 확인해보면 아까보다 훨씬 좋은 결과를 볼 수 있다.
하지만 여전히 과대적합 되어 있다. 이를 해결하려면 모델을 단순화 하거나 규제를 하거나 더 많은 데이터를 모으는 것이다.
7. 모델 미세 튜닝
1. 그리드 서치
과적합을 해결하는 가장 단순한 방법 중 하나로 하이퍼파라미터 조합을 찾을 때까지 수동으로 조정하는 방법이다.
사이킷런의 GridSearchCV를 사용하는 것이 좋다. 탐색하고자 하는 하이퍼 파라미터와 시도해볼 값을 지정하기만 하면 된다.
from sklearn.model_selection import GridSearchCV
full_pipeline = Pipeline([
("preprocessing", preprocessing),
("random_forest", RandomForestRegressor(random_state=42)),
])
param_grid = [
{'preprocessing__geo__n_clusters': [5, 8, 10],
'random_forest__max_features': [4, 6, 8]},
{'preprocessing__geo__n_clusters': [10, 15],
'random_forest__max_features': [6, 8, 10]},
]
grid_search = GridSearchCV(full_pipeline, param_grid, cv=3,
scoring='neg_root_mean_squared_error')
grid_search.fit(housing, housing_labels)
파이프라인이나 ColumnTransformer가 추정기를 겹겹이 감싸고 있더라도 추정기의 모든 하이퍼파라미터를 지정할 수 있다.
grid_search.best_params_
>>> {'preprocessing__geo__n_clusters': 15, 'random_forest__max_features': 6}
위와 같이 최상의 하이퍼파라미터 조합을 찾을 수 있다.
이 외에도 grid_search.best_estimator_ 속성을 사용해서 추정기를 얻을 수 있다.
GridSearchCV가 refit=True 로 초기화 되었다면 교차 검증으로 추정기를 찾은 후 훈련 세트로 다시 훈련한다.
cv_res = pd.DataFrame(grid_search.cv_results_)
cv_res.sort_values(by="mean_test_score", ascending=False, inplace=True)
# 추가 코드 – 데이터프레임을 깔끔하게 출력하기 위한 코드입니다
cv_res = cv_res[["param_preprocessing__geo__n_clusters",
"param_random_forest__max_features", "split0_test_score",
"split1_test_score", "split2_test_score", "mean_test_score"]]
score_cols = ["split0", "split1", "split2", "mean_test_rmse"]
cv_res.columns = ["n_clusters", "max_features"] + score_cols
cv_res[score_cols] = -cv_res[score_cols].round().astype(np.int64)
cv_res.head()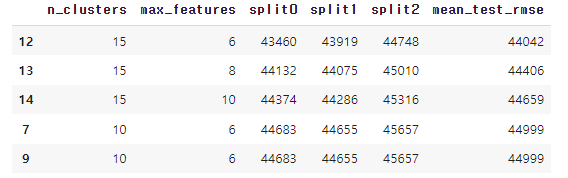
평가 점수는 grid_search.cv_results_ 속성으로 얻을 수 있다.
최상의 모델 평균 테스트 RMSE 점수는 44.042이다. 기본 파라미터 값을 사용해 얻은 점수 47.019보다 좋은 점수를 얻었다.
2. 랜덤 서치
그리드 서치는 적은 수의 조합을 탐구할 때 좋지만 탐색 공간이 커지면 RandomizedSearchCV가 선호된다.
랜덤서치의 장점은 다음과 같다.
- 그리드 서치는 하이퍼파라미터에 대해 나열된 몇 개의 값만 탐색하지만, 랜덤 서치는 모든 값을 탐색한다.
- 성능 면에서 큰 차이가 없을 때, 그리드 서치는 탐색 시간이 늘지만 랜덤 서치는 탐색 시간이 늘어나지 않는다.
- 랜덤 서치는 지정한 반복 횟수 만큼 실행할 수 있다.
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_distribs = {'preprocessing__geo__n_clusters': randint(low=3, high=50),
'random_forest__max_features': randint(low=2, high=20)}
rnd_search = RandomizedSearchCV(
full_pipeline, param_distributions=param_distribs, n_iter=10, cv=3,
scoring='neg_root_mean_squared_error', random_state=42)
rnd_search.fit(housing, housing_labels)
위 코드와 같이 하이퍼파라미터마다 가능한 값의 리스트나 확률 분포를 제공해야 한다.
작동 방식은 다음과 같다.
1. 첫 번째 반복에서 많은 하이퍼파라미터 조합이 그리드 서치나 랜덤 서치를 사용해 평가한다.
2. 이 후보들로 모델 학습과 교차 검증을 통해 평가를 진행한다.
3. 앙상블 방법
모델의 그룹이 최상의 단일 모델보다 더 나은 성능을 발휘할 때가 많다.
특히 개별 모델이 각기 다른 형태의 오차를 만들 때 그렇다. 예를 들면 k-최근접 이웃 모델을 훈련하고 랜덤 포레스트의 예측을 평균하여 예측으로 삼는 앙상블 모델을 만들 수 있다.
4. 최상의 모델과 오차 분석
RandomForestRegressor는 정확한 예측을 만들기 위한 각 특성의 상대적인 중요도를 알려준다.
final_model = rnd_search.best_estimator_ # 전처리 포함됨
feature_importances = final_model["random_forest"].feature_importances_
feature_importances.round(2)
sorted(zip(feature_importances,
final_model["preprocessing"].get_feature_names_out()),
reverse=True)
>>>
[(0.18694559869103852, 'log__median_income'),
(0.0748194905715524, 'cat__ocean_proximity_INLAND'),
(0.06926417748515576, 'bedrooms__ratio'),
(0.05446998753775219, 'rooms_per_house__ratio'),
(0.05262301809680712, 'people_per_house__ratio'),
(0.03819415873915732, 'geo__Cluster 0 similarity'),
[...] (0.00015061247730531558, 'cat__ocean_proximity_NEAR BAY'),
(7.301686597099842e-05, 'cat__ocean_proximity_ISLAND')]
중요도 점수를 내림차순으로 정렬한 것이다.
이 정보를 바탕으로 덜 중요한 특성들을 제외할 수 있다.
시스템이 특정한 오차를 만들었으면 문제의 원인을 알아야 한다. 그래야 해결 방법들을 찾을 수 있다.
이제 모델이 잘 작동하는 것 뿐만 아니라 모든 구역에서 잘 작동하는지 확인해야 한다.
5. 테스트 세트로 시스템 평가하기
X_test = strat_test_set.drop("median_house_value", axis=1)
y_test = strat_test_set["median_house_value"].copy()
final_predictions = final_model.predict(X_test)
final_rmse = mean_squared_error(y_test, final_predictions, squared=False)
print(final_rmse)
>>> 41424.40026462184
이 추정값이 얼마나 정확한지 알고 싶을 땐 scipy.stats.t.interval()을 사용해 신뢰구간을 측정한다.
from scipy import stats
confidence = 0.95
squared_errors = (final_predictions - y_test) ** 2
np.sqrt(stats.t.interval(confidence, len(squared_errors) - 1,
loc=squared_errors.mean(),
scale=stats.sem(squared_errors)))
>>> array([39275.40861216, 43467.27680583])
신뢰구간 39,275와 43,467 사이로 이전 점 추정값인 41,424는 대략 중간에 해당한다.
우리 시스템은 검증 데이터에서 좋은 성능을 내도록 세밀하게 튜닝되었기 때문에 새로운 데이터셋에서는 제대로 작동하지 않을 가능성이 크다. 하지만 이런 경우가 생기더라도 성능 수치를 좋게 하려고 하이퍼파라미터를 튜닝하려 시도하면 안된다. 그렇게 되면 새로운 데이터에 일반화 되기가 어렵다.
8. 론칭, 모니터링, 시스템 유지 보수
솔루션 론칭 허가를 받은 후 모델을 제품 환경에 배포할 수 있다,
가장 기본적인 방법은 모델을 저장하고 제품 환경으로 파일을 전달해 로드한다.
import joblib
joblib.dump(final_model, "my_california_housing_model.pkl")
1. 최종 모델을 저장한다.
2. 모델이 사용하는 모든 클래스 및 함수를 임포트한 후 모델을 로드하고 예측한다.
3. 모델을 배포한다.
4. 일정 간격으로 모델의 실시간 성능을 체크하면서 유지한다.
5. 모든 모델과 데이터셋의 버전을 백업해서 필요 시 빠르게 롤백할 수 있도록 한다.
6. 프로젝트를 제품화하려면 모델 개발, 배포, 운영, 모니터링, 롤백 등 전 과정이 포함된 MLOps 개념이 필수적이다.
'ML' 카테고리의 다른 글
| [Machine Learning][3] 분류 (2) (0) | 2025.03.11 |
|---|---|
| [Machine Learning][3] 분류 (1) (0) | 2025.03.10 |
| [Machine Laerning][2] 머신러닝 주요 단계 (2) (0) | 2025.03.05 |
| [Machine Learning][2] 머신러닝 주요 단계 (1) (0) | 2025.03.04 |
| [Machine Learning][1] 머신러닝 (0) | 2025.03.03 |



