인공지능이란 인간이나 다른 동물의 지능과는 달리, 기계나 소프트웨어의 지능을 의미한다.
인공지능은 지능적인 기계를 개발하고 연구하는 컴퓨터 과학의 한 분야이다.
'지능'은 여러 방식으로 정의되어왔다.
예를 들면 추상화, 논리, 이해, 자기 인식, 학습, 감정적 지식, 추론, 계획, 창의성, 비판적 사고, 문제 해결 능력 등이 있다.
지능은 정보를 지각하거나 추론하는 능력, 그리고 그것을 지식으로 저장하여 환경이나 상황 속에서 적응적인 행동에 활용하는 능력으로 설명될 수 있습니다.
AI가 구현되는 방법에는 두 가지가 있다.
1. Rule-based system (규칙 기반 시스템)
- 사람이 직접 IF-THEN 같은 규칙을 작성하는 방식
- 설명하기는 쉽지만 사람이 일일이 규칙을 짜야 한다.
2. Learning from data (데이터로부터 학습)
- 데이터를 통해 자동으로 학습하는 방식
- 데이터가 많을 수록 성능 향상
- 사람이 직접 규칙을 안 짜도 되지만 내부 작동이 불투명할 수도 있다. (black box)
우리가 배우는 딥러닝은 대부분 이 데이터 기반 학습에 속한다.
AI, ML, DL는 AI > ML(머신러닝) > DL(딥러닝) 순서로 포함 관계가 있다.
머신러닝은 AI의 한 분야로 데이터로부터 학습하고 보지 않은 데이터에도 일반화할 수 있는 통계적 알고리즘을 개발하고 연구하는 분야이다.
지도학습 (Supervised learning)는 입력 x와 정답 y의 example, label이 주어진다.
학습이 완료되면 새로운 데이터 y를 예측할 수 있다.
비지도학습 (Unsupervised learning)은 정답 없이 데이터만 주어진다.
모델이 데이터 자체에서 패턴을 스스로 학습한다.
머신러닝은 데이터 기반 접근 방식이다.
지도학습의 프레임워크는 다음과 같다.
step 1. 인간은 모델의 형태를 디자인만 한다. (f(x) = ax)
step 2. 이 모델이 학습할 목표를 정한다. ( y가 f(x)에 최대한 가까워지도록 -> y ≈ ax)
step 3. 학습 데이터를 바탕으로 목표를 최적으로 달성하는 파라미터(a)를 찾는다.
step 4. 새로운 입력 x가 주어지면 학습된 모델로 레이블을 추정할 수 있다. ( ŷ = ax)
Overview of machine learning
예시 하나를 보자.
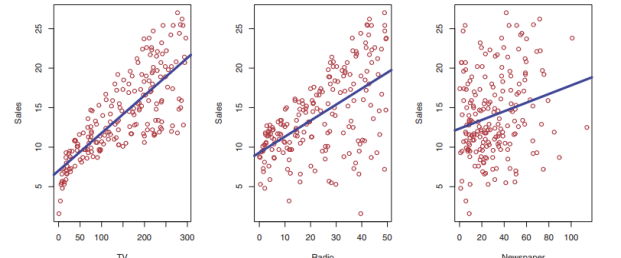
- TV, 라디오, 신문 광고 예산으로 매출을 예측
- 첫 번째 시도 : 각각 따로 선형회귀 적합해보기 ( Sales ≈ 𝑓1(TV), Sales ≈ 𝑓2(Radio), Sales ≈ 𝑓3(Newspaper) )
- 더 나은 방법은 모든 입력을 함께 고려하는 모델 사용 Sales ≈ 𝑓(TV, Radio, Newspaper)
여기서 Sales는 우리가 예측하고자 하는 타겟, 라벨, 응답 (y) 값이다.
TV, 라디오, 신문은 입력 특징값 또는 예측 변수 x1,x2,x3이다.
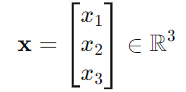 |
 |
입력들을 왼쪽 그림과 같이 벡터로 묶어서 쓸 수 있다.
모델은 오른쪽과 같이 ℝ³ → ℝ 함수로 쓸 수 있다.
여기서 𝜖(엡실론)은 측정 오차나 예측 오차로 x와는 독립적이다.
f(x)는 모델이라 부르며, 입력값 x를 받아 출력값 y를 생성한다.
여기서 x와 y는 스칼라일 수도 있고 벡터일 수도 있다.
하지만 우리는 f(x)가 아무 y나 출력하는 것을 원하는 것이 아니라 다양한 x에 대해 좋은 y를 예측하는 f를 원한다.
좋은 회귀 함수를 이용하면 어떤 x가 y를 설명하는데 중요한지, 어떤 x가 별로 중요하지 않은지 파악이 가능하다.
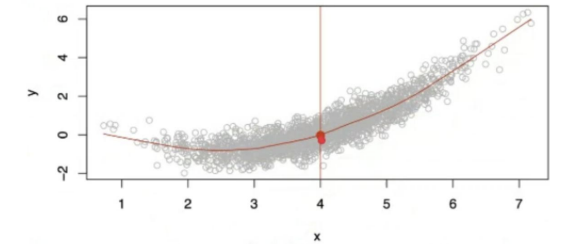
위 그래프에서 x = 4일 때 좋은 f(x)의 값은 여러 개일 수 있다.]우리가 원하는 좋은 예측값은 f(4) = E[y|x=4] 이다.
E[y|x=4]는 x=4일 때 y의 기대값 (평균)을 의미한다.
즉, 우리는 특정 x=4일 때만이 아니라 모든 x 값에 대해 이 기대값을 예측하길 원한다.
step 1. 모델 f를 어떻게 설계할까?
이 문제에 대한 대부분 학습 방법은 parametic 아니면 nonparametric 모델로 나뉜다.
parametric 모델은 입력값 x와 출력값 y 사이의 관계를 수학적 형태로 제한하고 유한한 개수의 파라미터로 정의된다.
예시로 선형 회귀 모델이 있다.

선형 모델은 입력값을 선형 결합하여 y를 예측하는 구조이다.
파라미터는 편향을 포함해 총 d+1개이다.
파라미터들은 학습 데이터에 맞게 피팅되어 결정된다.
실제 데이터에 선형 모델이 완벽히 들어맞는 경우는 없지만 실제 함수를 근사하는데는 좋다.

parametirc 모델의 경우 함수 f를 추정하기 위해 사용하는 형태 자체가 실제 함수와 다를 수 있다.
nonparametirc 모델은 f의 형태에 대해 사전 가정을 하지 않기 때문에 이런 위험을 피할 수 있다.
하지만 정확한 함수를 추정하려면 훨씬 더 많은 관측값이 필요하다.
step 2. 모델 f(x)의 목적 정의
우리는 y ≈ f(x)가 되길 원한다. 이걸 수학적으로 표현하면,
가능한 모든 입력 x에 대해 f(x) = E[y|x]를 만족하기 원한다.
즉, f(x)는 x가 주어졌을 때 y의 평균값을 추정하는 함수가 되어야 한다.
모든 입력 x에 대해 예측 오차를 E[(y-f(x))^2] 최소화하는 것은 위에 조건과 같게 된다.

왼쪽은 전체 MSE이고 오른쪽 첫 항은 줄일 수 있는 오차 (reducible error), 두 번째는 노이즈로 인한 오차 (irreducible error)이다.
우리가 f(x)를 잘 알고 있다고 해도 같은 x에서 나올 수 있는 y의 값들은 확률적으로 분포되어 있기 때문에 항상 예측 오차는 존재한다.
그래서 우리는 줄일 수 있는 오차 (reducible error)를 줄이기 위한 f 추정 방법에 초점을 둔다.
step 3. 함수 추정 방법
보통 우리는 서로 다른 n개의 데이터를 관측하고 이 값들을 학습 데이터 (training data)라고 부른다.
이 데이터를 이용해 함수 f를 어떻게 추정할지를 학습한다.
즉, 어떤 입력 x가 주어졌을때 그에 대응하는 출력 y와 최대한 잘 맞도록 f(x)를 찾는 것이다.
이 과정을 최적화 (optimization)이라고 부른다.
optimization으로 한 번에 답을 구하는 것이 가능하면 해석적인 해(closed-from solution)를 사용하고,
그렇지 않으면 경사 하강법 (gradient desent), 수치적 방법 (numerical methods) 가 일반적으로 사용된다.
step 4. 모델 성능 평가
학습 데이터 𝒟𝑡𝑟𝑎𝑖𝑛 = {𝑥 (𝑖) , 𝑦 (𝑖)}를 사용해서 모델 f^(x)을 학습했다고 하자.
이 모델이 얼마나 잘 작동하는지 확인하려면 우선 학습 데이터에 대한 MSE를 계산한다.

하지만 이 값은 모델이 과적합 될 수록 더 낮게 나올 수 있다.
그래서 학습에 사용되지 않은 테스트 데이터를 이용해서 평가한다.


테스트 오차와 학습 오차를 비교해보면 더 복잡한 모델을 학습 오차는 작지만 테스트 오차가 터질 수 있다.
따라서 적절한 복잡도의 모델을 선택하는 것이 중요하다.
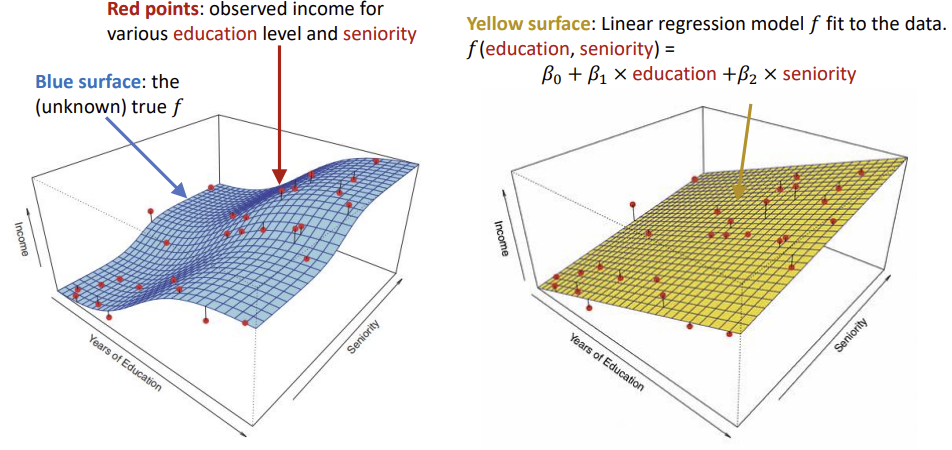 |
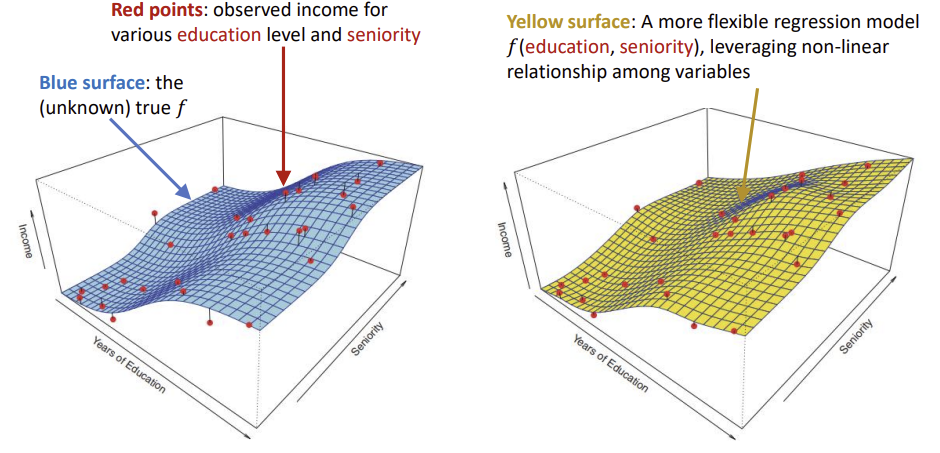 |
 |
첫 번째 사진은 선형 회귀 모델로 단순하고 해석이 쉽지만 진짜 곡면과 차이가 크다.
두 번째 사진은 조금 더 유연한 비선형 회귀 모델로 관측값에 더 잘 맞는다.
세 번째는 매우 유연한 모델로 학습 데이터에는 완벽하게 맞지만 과적합이 발생할 수 있다.
- 좋은 예측 성능 vs. 과적합/과소적합
학습 정확도가 높아도 새로운 데이터에 잘 작동하지 않을 수 있다.
- 예측 정확도 vs. 해석 가능성
선형 모델은 해석이 쉽지만 정확도는 낮을 수 있고 비선형 모델은 정확하지만 해석이 어려울 수 있다.
- 단순한 모델 vs. 복잡한 모델
우리는 모든 변수에 의존하는 복잡한 모델보다 적은 변수로 설명 가능한 단순한 모델을 선호한다.

테스터 데이터가 주어졌을 때, 그에 대한 예측 오차의 기대값은 다음과 같이 나뉘어진다.

Bias : 모델이 f(x)와 얼마나 차이가 나는지 / Variance : 모델이 학습 데이터에 얼마나 민감하게 반응하는지 / Var(ε) : 줄일 수 없는 오차
보통 모델이 유연질 수록 Bias는 줄지만 Variance는 커진다.
그래서 MSE를 기준으로 적절한 유연성 수준을 선택해야 한다.
Classification problems
분류 문제에서 출력값 y는 범주형 값이다.
예를 들면 이메일이 스팸인지 아닌지, 숫자 이미지가 0부터 9 중에 어떤 숫자인지 출력하는 것이다.
우리의 목표는 다음과 같다.
- 미래의 데이터 x가 주어졌을 때, x에 대해 적절한 클래스 라벨을 지정하는 f(x)를 만들기
- 각 분류에 대한 불확실성을 추정하기
- 입력 벡터 X = (x1, x2, ..., xn)에서 어떤 변수들이 중요한지 이해하기
보통 분류기의 성능은 오분류율 (misclassification error ratte)로 평가한다.

이미지 분류 (Image classification)은 머신러닝 핵심 과제 중 하나이다.
주어진 이미지에 대해 라벨이 (dig,cat,rabbit...)과 같은 클래스 중 하나로 되어있다.
모델은 이 이미지를 보고 어떤 클래스인지 맞추는 걸 학습한다.
K-Nearest Neighbors은 입력 이미지가 주어졌을 때, 가장 비슷한 k개의 학습 이미지를 찾아서 이미지의 라벨을 보고 가장 많이 나온 클래스로 예측 값을 사용한다.
각 클래스 j에 대해 다음과 같은 조건부 확률을 추정한다.

최종 분류에서는 가장 높은 확률을 가진 클래스를 선택한다.
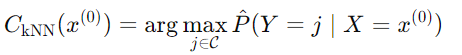
K-NN은 비모수적(nonparametic) 모델의 좋은 예이다.
학습 데이터를 모두 기억하고 그 데이터를 바탕으로 직접 예측한다.
선형 회귀처럼 어떤 형태의 수식에 파라미터를 맞추는 방식이 아니다.
'Major Study > 25-1 Deep Learning Application' 카테고리의 다른 글
| [Deep learning Application] Lecture 6 : Neural Network (0) | 2025.04.27 |
|---|---|
| [Deep learning Application] Lecture 5: Image Classification (1) | 2025.04.25 |
| [Applied Deep Learning] Lecture 4. Logistic Regression (0) | 2025.04.06 |
| [Deep learning application] Lecture 3. Linear regression (0) | 2025.03.29 |



