
Input Embedding
Step1. 입력 임베딩

- 입력은 토큰 임베딩 시퀀스로 표현된다.
- 각 토큰은 동일한 차원의 벡터로 매핑된다.
Multi-Head Attention
step2. 임베딩의 문맥화
- 각 입력 임베딩 xi는 세 가지 다른 벡터로 표현된다.

- WQ, WK, WV는 학습 가능한 선형 변환 행렬이다.
- 초기엔, 단순한 X에서 뽑아낸 랜덤 행렬이지만 학습을 하면서 각각의 의미를 가진다.
- Q : 토큰이 찾고자 하는 정보, K : 토큰이 제공할 수 있는 정보, V : 실제 포함하고 있는 정보
- 각 쿼리는 모든 키 벡터와 유사도를 계산해 입력 토큰 x가 자신뿐만 아니라 다른 모든 토큰으로부터 정보를 모아 새롭게 표현되는 z를 만든다.

- 만약 벡터의 차원 dk가 너무 크다면 분산이 커지고, softmax 값이 너무 크거나 작아지는 문제가 생긴다.
- 위 문제를 방지하기 위해 1 / (dk^1/2) 로 정규화를 적용한다.

- temperature 매개변수 τ를 도입해서 적절한 분포를 만들어줄 수도 있다.
- τ가 작으면 출력 분포가 날카로워지고, 클수록 출력 분포가 평평해진다.

- 만약 Attention Head가 하나라면 토큰 간 단일 관계 유형만 포착할 수 있다.
- 여러 헤드를 병렬로 두면 각 헤드가 다양한 관계를 동시에 학습이 가능하다.
- > 트랜스포머 내부의 여러 헤드들은 문장의 다양한 문법 구조를 동시에 학습하는 병렬 해석기 역할을 한다.


- 각 헤드의 출력을 concat 해서 Wo로 선형 변환을 통해 원래 차원 d로 돌려놓는다.
- > H개의 어텐션 헤드가 병렬로 문맥 정보를 수집하고, 병합 후 FC층을 통해 정보를 통합한다.
Add & Norm, Feed Forward, Add & Norm
step3. 위치별 피드포워드 계층
- 각 문맥화된 토큰 임베딩은 개별적으로 FFN을 거쳐 더 정교하게 변환된다.

- FFN은 각 토큰마다 독립적으로 적용된다.
- 출력 차원은 입력 임베딩과 동일하게 유지된다.
- Residual Connection과 Layer Normalization이 추가되어 학습 안정성을 높인다.
- 하나의 트랜스포머 인코더는 여러개의 동일한 인코더 블록을 쌓아 구성된다.
- > 첫번째 레이어의 입력은 토큰 임베딩이고, 그 이후 레이어의 입력은 이전 블록의 출력이다.
- 블록을 쌓을 수록 각 토큰 임베딩은 더 깊은 문맥 정보를 내포한다.
- Self-Attention은 순열 분별 구조이다.
- > 입력 토큰의 순서를 바꾸어도 동일한 결과를 낸다.
- 그러나 시퀀스 데이터는 순서가 매우 중요하기 때문에 Positional Encoding을 도입한다.
- RNN과 달리 트랜스포머는 순서를 내재적으로 처리하지 않기 때문에 각 토큰 위치 t에 해당하는 위치 벡터 pt를 추가로 더해준다.
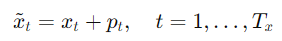
- 위치 인코딩은 두 가지의 종류가 존재한다.
1. 학습 가능 방식
- 각 위치 pt를 학습 가능한 파라미터로 둔다.
- Tx X d 크기의 lookup table로 구현된다.
- 모델이 학습 중 위치 표현을 스스로 최적화할 수 있다.
2. 고정식 방식
- 사인/코사인 함수를 이용해 위치 정보를 생성한다.

- > i가 낮을 수록 빠르게 진동하면서 근처 위치를 구분하고, 높을 수록 느리게 진동하면서 전체 순서를 인식한다.

Output Embedding
step4. Decoder Input
- 디코더 입력은 타깃 시퀀스의 토큰 임베딩이다.

- 디코더 입력은 실제 문장의 정답 시퀀스를 한 칸 오른쪽으로 이동시킨 형태이다.

- 위치 인코딩은 인코더와 동일하게 작용한다.
step5. Masked Multi-Head Self-Attention
- 디코더는 현재 시점 이전의 정보만을 이용해서 단어를 예측해야 한다.
- 추론시 한 번에 하나의 단어만 생성하고, 학습 시에는 모든 시점에서 정답 단어가 제공된다.
- 하지만 각 시점은 '미래 단어'를 보지 못하도록 해야 한다.

- 어텐션 점수에다가 마스크 행렬 M을 더한다.
- > 미래 단어에 대한 점수는 softmax 단계에서 0이 되어 무시된다.
- 그 후, softmax로 정규화하여 현재 시점 이전의 토큰에 대해서만 어텐션이 작동한다.
step6. Encoder-Decoder Attention (Cross-attention)
- 디코더는 인코더 출력 전체 Z=[z1,z2,…,zTx] 를 참조하여 출력 단어를 생성한다.
- 디코더는 입력 문장의 모든 단어를 참고해야 하기 때문에 마스크를 적용하지 않는다.
- cross-attention을 통해 입력 문장의 어느 부분에 주목해야 하는지 학습한다.
- Masked Multi-Head Self-Attention : 디코더 입력 내부의 문맥을 학습
- Cross-Attnetion : 인코더의 출력과 디코더의 현재 상태를 연결한다.
- FFN : 각 토큰 임베딩을 비선형 변환으로 정제
step7. Linear Layer & Softmax
- 디코더의 마지막 출력은 각 시점의 은닉 상태 zt이다.
- 이를 선형 계층을 거쳐 어휘 크기만큼 차원을 변환한다.

- 이후 softmax를 통해 확률 분포를 얻는다.

- 출력 단어 선택 방법은 다음과 같은 방법이 있다.
1. Greedy Search : 확률이 가장 높은 단어를 선택한다.
2. Sampling : softmax 확률 분포에서 무작위 샘플링을 한다.
3. Beam Search : 여러 후보를 병렬 탐색해 가장 가능성이 높은 문장을 선택한다.
- 특정 task에 따라 임베딩된 z는 classifier나 regressor로 처리될 수 있다.
- > Token aggregation
- 입력 시퀀스의 맨 앞에 특수 분류 토큰 [CLS]을 추가한다.
- Self-Attention 과정에사 [CLS] 토큰은 다른 토큰들을 참고하여 task와 관련된 정보를 요약하는 역할을 학습한다.
- [CLS] 토큰의 임베딩은 학습 가능한 파라미터로 설정된다.
- 이 벡터는 분류기에 입력되어 최종 예측을 수행한다.
- 트랜스포머는 두 가지 학습 유형이 있는데,
1. Sequence-level supervision
- 전체 입력에 대해 하나의 라벨만 존재한다.
- [CLS] 토큰을 사용한다.
- Classifier로 하나의 y_hat을 낸다.
2. Token-level supervision
- 각 토큰마다 라벨이 존재한다.
- Classifier로 여러가지의 y_hat을 낸다.
ViT: Vision Transformer

1. 입력 이미지
- 이미지를 P x P 크기의 패치(patch)로 분할한다.
2. 패치 임베딩
- 각 패치를 flatten 후 하나의 벡터로 펼친다.
- linear projection으로 임베딩 공간으로 변환한다.
3. [CLS] 토큰 추가
- 텍스트 트랜스포머와 동일하게 [CLS] 토큰을 추가해 전체 이미지의 전역 표현을 담당한다.
4. 위치 인코딩
- N+1개의 토큰([CLS] + N개 패치)에 대해 위치 임베딩을 더한다.
- ViT는 학습 가능한 위치 임베딩을 사용한다.
- > 모델이 직접 위치 정보를 데이터로부터 학습하도록 설계
- 서로 가까운 패치들은 비슷한 위치 임베딩을 가지고, 멀리 떨어진 패치는 다른 위치 정보를 학습한다.
- ViT는 시퀀스 길이가 고정되어 있기 때문에 긴 문장을 다룰 필요가 없다.
- 따라서, 학습 가능한 2D 위치 임베딩으로 충분하다.
- ViT는 데이터가 작을 땐 CNN보다 비효율적이지만, 데이터가 커질수록 ViT가 압도적이다.
- 귀납적 편향이란 알고리즘이 데이터에 대해 가지는 가정의 집합을 의미한다.
- 귀납적 편향은 모델이 제한된 데이터로도 효율적으로 학습하고 보편화를 잘하도록 돕는다.
- 모델 설계나 사전 지식을 통해 학습 과정에 도메인 지식을 주입하는 방법이다.
- CNN에서의 귀납적 편향은 공간적 지역성, 이동 불변성이 있고,
- RNN에서는 순차적 의존정, 시간 불변성 등이 있다.
- Transformer는 낮은 귀납적 편향으로 데이터 간 관계를 모델이 스스로 찾아낸다.
- 귀납적 편향이 높으면 학습이 빠르고 적은 데이터도 학습이 가능하지만 가정이 틀리면 성능이 저하된다.
- 귀납적 편향이 낮으면 데이터로부터 직접 학습하고 더 일반화된 표현을 얻지만, 더 많은 데이터와 학습 비용이 증가한다.
- Transformer는 장거리 의존성을 다루는데 강하고 확장성이 높고 입력 구조에 대한 가정이 거의 없기 때문에 파운데이션 모델에 적합하다.
* 파운데이션 모델 : 대규모의 다양하고 방대한 데이터로 사전 학습된 대형 모델로 미세조정하여 사용가능하다.
- ConvNext는 Transformer에 맞게 재설계된 CNN이다.
1. 큰 커널 크기
2. Layer Normalization
3. 활성화 함수 ReLU - > GELU
4. 간소화된 구조 : 복잡한 구성 대신 효율성과 확장성 강조
5. 데이터 중심 설계
- ViT는 훈련 효율성이 낮고 많은 데이터와 연산 자원을 필요로 하는 단점이 있어 DeiT가 등장하였다.
1. CutMix, Mixup, RandAugment 등 강력한 데이터 증강 기법 적용
2. DropPath, Label Smoothing 등 정규화 강화
3. Self-Distillation 등 새로운 학습 전략 도입
4. 낮은 해상도에서 훈련 후, 높은 해상도로 파인튜닝
- Transformer는 객체 탐지, 세분화, 생성 모델 등 다양한 분야에서 성능을 보이고 있다
- 대규모 멀티모달 학습을 통해 텍스트 + 이미지를 동시에 이해하고 생성하는 VLMs (Vision-Language Models)이 등장했다.
'Major Study > 25 Deep Learning Application' 카테고리의 다른 글
| [Deep Learning Application] Lecture 9 : Sequential Models II (0) | 2025.10.09 |
|---|---|
| [Deep Learning Application] Lecture 8 : Sequential Models I (0) | 2025.10.06 |
| [Deep Learning Application] Lecture 7 : Convolutional Neural Networks (0) | 2025.09.23 |
| [Deep Learning Application] Lecture 6 : Neural Network (0) | 2025.04.27 |
| [Deep Learning Application] Lecture 5: Image Classification (1) | 2025.04.25 |
