01 데이터 수집과 전처리
데이터 수집
- 관찰과 측정으로 원시 데이터(raw data)를 생성한다.
데이터 전처리 (data pre-processing)
- 데이터베이스에 보관 불가능한 원시 데이터를 데이터베이스에 보관/관리/검색이 가능한 가공데이터로 바꾼다.
데이터 전처리 진행에 따른 데이터 분류
원시데이터 (raw data)
- 최초의 현실에서 얻어진 데이터이다.
- 데이터베이스에 보관이 불가능하다.
ex) 영수증, 이미지, 영상 ...
중간데이터(intermediate data)
- 원시데이터를 데이터베이스에 보관이 가능하게 만드는 과정의 중간데이터이다.
- 하지만 여전히 보관은 안 된다.
ex) 종이영수증을 스캔해서 얻은 jpg파일
가공데이터(processed data)
- 원시데이터를 가공해서 데이터베이스 보관이 가능한 데이터
ex) 영수증 엑셀 파일
데이터 전처리 순서
1. 자료 선택 및 배제
-> 영수증 데이터이면 계약서, 성적표 자료는 배제
2. 전산화
- 영수증 종이 다발은 컴퓨터로 인식이 불가능하다. -> 스캔으로 전산화
- 영수증 스캔 이미지는 컴퓨터로 인식이 불가능하다. -> OCR로 기호화
3. 구조화 및 정형화 (데이터베이스에 보관하려면)
- 비정형 영수증 텍스트 구조를 데이터베이스에 보관 가능하게 구조화한다.

02 데이터 구조화
데이터 구조화
- 데이터의 구조 정보를 체계적으로 표시한다.
ex) 지원서 텍스트 -> 구조화된 지원서
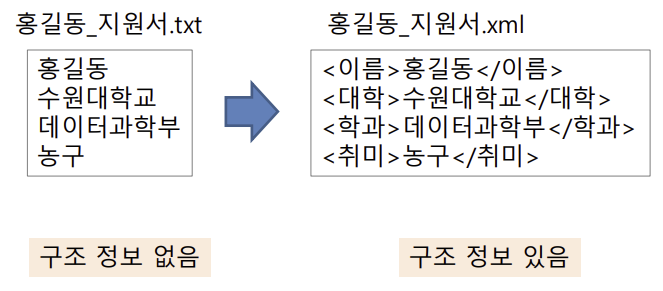
데이터 구조화의 필요성
- 구조화 된 데이터에서 관리/검색이 가능하다.
ex) 수원대학교 학생을 선택해줘 -> txt 파일은 비구조화 되어있어서 대학을 나타내는 부분이 어디인지 알 수 없어 조건 선택이 불가능하다.
xml 파일은 대학을 나타내는 부분이 어디인지 알 수 있으므로 선택이 가능하다.
데이터 정형화
- 데이터의 구조 정보를 통일해서 표로 만든다.
ex) 개별적으로 구조화된 이력서를 통일한 항목으로 만든다.

데이터 표현 방식
1. 논리적 층위 표현 형식
- 논리적으로 이해하는 표현형식이다.
- 반정형데이터의 논리적 표현 : 키-값(key-value)
- 정형데이터의 논리적 표현 : 테이블(table)
2. 물리적 층위 표현 형식
- 약속된 작성 규칙에 따라 실제 디스크에 기록되는 형식이다.
- 반정형 데이터의 물리적 표현 : json, xml
- 정형 데이터의 물리적 표현 : csv, tsv, xlsx

반정형데이터의 논리적 표현
key-value
: 구조 정보를 속성과 값(key, value)의 쌍으로 나타낸다.
- 중첩구조를 표현할 수 있다.
(이름, 홍길동)
(대학, 수원대학교)
(나이,21)
(학과, (
(학과명, 데이터과학부),
(위치, 글로벌경상관),
)
)
(취미,농구)
JSON (JavaScript Object Notation)
- 문자는 큰따옴표로 쓰고, 숫자는 큰따옴표로 쓰지 않는다.
{
"이름" : "홍길동",
"대학" : "수원대학교",
"나이" : 21,
"학과" : {
"학과명" : "데이터과학부",
"위치" : "글로벌겨경상관"
}
"취미" : "농구"
}
XML (Extensible Markup Language)
<이름>홍길동</이름>
<대학>수원대학교</수원대학교>
<나이>21</나이>
<학과>
<학과명>데이터과학부</학과명>
<위치>글로벌경상관</위치>
</학과>
<취미>농구</농구>
정형데이터의 논리적 표현
Table

- 개별 데이터는 행으로 속성은 열로 나타낸다.
- 첫번째 행에는 속성의 정보를 기입한다.
CSV

- 문자열은 헷갈린다고 판단되면 선택적으로 ""를 사용하고 값에 "가 있으면 두 번 사용한다.
정형데이터의 물리적 표현
TSV (tab-separated values)
- csv와 동일하고 구분자로 탭(tab, \t)문자를 사용한다.
- 구분자는 데이터 값에서 사용되지 않은 문자일 수록 유리하기 때문에 쉼표(,)보다 탭(tab)을 구문자로 사용하는 장점이 있다.
XLS, XLSX
- 엑셀에서 사용하는 포맷이다.
- 표와 그 내용 값을 엑셀 소프트웨어 전용 규칙에 따라서 저장한다.
- 일반 편집기로 읽을 수 없고 엑셀 소프트웨어로만 읽고 편집이 가능하다.
비정형, 반정형, 정형 데이터 사이의 관계
* 비정형 데이터 - 반정형데이터 - 정형데이터 *
-> 정형데이터 방향으로
1. 구조화가 잘 되어있다.
2. 작업에 비용이 적게 든다.
-> 비정형 데이터 방향으로
1. 초기 비용은 적게 든다.
2. 더 많은 지식을 얻은 후 구조화할 수 있다. ex) 자연어처리, 이미지 인식
3. 정보손실이 적다.
따라서 전체 작업을 고려한 적절한 구조화가 중요하다.
.open chapter2.sqlite3
create table 거래명세서(거래일자 varchar(10), 구매자상호 varchar(10), 구매자주소 varchar(20),
구매자전화번호 varchar(13), 공급자 상호 varchar(20), 공급자등록번호 varchar(20),
품명 varchar(20), 규격 varchar(20), 수량 int, 단가 int);
.schema
insert into 거래명세서 values('2017-01-04','미래산업','서울시 강남구 대치동','050-5570-2300','지디소프트',
'410-2137387',' 삼성프린터','MLS200',1,180000);
insert into 거래명세서 values('2017-01-04','미래산업','서울시 강남구 대치동','050-5570-2300','지디소프트',
'410-2137387','엘지무선키보드','K820',1,22000);
.mode table
slelct * from 거래명세서;
'Major Study > 25-1 Database' 카테고리의 다른 글
| [Database] 06 데이터입력 SQL (3) | 2025.04.18 |
|---|---|
| [Database] 05 관계형 데이터 모델 (0) | 2025.04.17 |
| [Database] 04 관계형 데이터 모델과 릴레이션 (0) | 2025.04.17 |
| [Database] 03 데이터베이스 설계 (0) | 2025.04.17 |
| [Database] 01 데이터베이스 시스템 (2) | 2025.04.08 |



