01 릴레이션 용어
테이블
- 정형 데이터를 보관하는 직관적이고 효과적인 데이터 구조이다.
ex) 회원 테이블 : 회원들의 데이터를 보관

- 두 종류의 질적 정보 (구조 정보, 값 정보)로 구성된다.
테이블의 2가지 구성 정보
- 구조정보 : 테이블의 구조에 대한 정보이다.
ex) 이름, 출생년도, 주소
- 최초 테이블이 정의될 때 내재된다. (정적특성) -> 내포(intention)이라 부른다.
- 값정보 : 구체적인 값 정보이다.
ex) (“강호동”, 1970, “대전”), (“유재석“, 1972, “경북“), (“신동엽“, 1971, “광주“)
- 최초 테이블이 정의된 이후 바깥의 데이터에 의해 확장된다. (동적특성) -> 외연(extension)이라 부른다.
구조 정보의 구성
- 이름 정보 : 데이터의 대상을 표현하는 정보
-> 엑셀에 저장할 때, '스프레드시트의 이름'에 해당된다.
ex) 회원 테이블에서 '회원'
- 속성 정보 : 데이터의 대상의 속성에 대한 정보
-> 엑셀에 저장할 때, '머릿줄'에 해당한다. (필드라고도 한다.)
ex) 회원 테이블에서 (이름, 출생년도, 주소)
- 도메인 정보 (옵션) : 테이블이 저장하는 대상의 속성이 가질 수 있는 값의 영역에 대한 정보이다.
-> 엑셀에서는 보통 서식으로 입력한다.
ex) 이름 : {길이 10자 이내의 문자열}, 출생년도: {0이상 3000이하의 정수}, 주소: {“서 울”, “경기”, “대전”, “강원”, “경북”, “광주”, ...}
값 정보
- 테이블의 구조 정보에 해당하는 구체적인 데이터 값
- 레코드(record) : 데이터 하나를 가르킴
ex) 회원 테이블에서 첫번째 레코드는 (“강호동”, 1970, “대전”)이다.
테이블에 대한 용어의 다양성
- 데이터베이스 이론, 시스템, 소프트웨어 분야에서 독립적으로 테이블을 사용해왔다.
-> 분야마다 테이블에 대한 용어가 다르다.
ex) 데이터베이스 이론 전문가 : '릴레이션'을 하나 만드세요.
시스템 전문가 : '테이블'을 하나 만드세요.
소프트웨어 전문가 : '스프레드시트'를 하나 만드세요.
스키마(shema)
- 릴레이션의 구조 정보이다. -> 이름, 속성, 도메인으로 구성되어 있다.
- 이름 : 릴레이션이 표현하고자 하는 대상의 이름이다. ex) 회원 릴레이션
- 속성 : 릴레이션이 표현하고자 하는 대상의 특성이다. ex) 이름, 출생년도, 주소
- 도메인 : 속성이 가질 수 있는 값의 집합이다. ex) 이름 : {길이 10자 이내의 문자열}, 출생년도: {0이상 3000이하의 정수}, 주소: {“서 울”, “경기”, “대전”, “강원”, “경북”, “광주”, ...}
인스턴스(instance)
- 릴레이션의 데이터 정보이다.
ex) {(“강호동”, 1970, “대전”), (“유재석“, 1972, “경북“), (“신동엽“, 1971, “광주“)}
- 튜플 (tuple) : 인스턴스를 이루는 벡터 하나를 가르킨다. ex) 첫 번째 튜플은 (“강호동”, 1970, “대전”)
릴레이션(relation)과 테이블(table)
- 릴레이션과 테이블은 상호 호환된다.

널 값, 차수, 카디널리티
- 널(null) : 속성 값을 아직 잘 모르거나 해당되는 값이 없음을 표현한다. ex) 유재석의 주소를 모른다.
- 차수(degree) : 하나의 릴레이션에서 속성의 전체 개수 ex) 이름, 출생년도, 주소 = 3
- 카디널리티(cardicality) 또는 기수 : 하나의 릴레이션에서 튜플의 전체 개수 ex) 회원 테이블의 타디널리티 = 3

도메인 표기법 (SQL)

데이터베이스의 구성
- 데이터베이스 스키마 : 데이터베이스의 전체 구조이다. -> 데이터베이스를 구성하는 릴레이션 스키마의 모음
- 데이터베이스 인스턴스 : 데이터베이스를 구성하는 릴레이션 인스턴스의 모음

관계 데이터베이스 모델에서 릴레이션의 특성 (규칙)
- 집합의 수학적 성질을 만족하기 위한 규칙이다.
1. 튜플의 유일성 : 하나의 릴레이션에는 동일한 튜플이 존재할 수 없다.

-> 이 릴레이션은 동일한 튜플로 인해 릴레이션으로 성립 안 한다.
-> 만약 첫번째와 두번째가 다른 인물이라면, 둘을 구별하는 식별자가 필요하다.
2. 튜플의 무순서성 : 하나의 릴레이션에서 튜플 사이의 순서는 무의미하다.

-> 강호동, 유재석 튜플 순서가 바뀌었지만 동일한 릴레이션으로 취급한다.
3. 속성의 무순서성 : 하나의 릴레이션에서 속성 사이의 순서는 무의미하다.

-> 출생년도와 성별의 속성이 바뀌었지만 동일한 릴레이션으러 취급한다.
4. 속성의 원자성 : 속성 값으로 원자 값만 사용할 수 있다.

-> 강호동의 주소값이 서울, 대전의 다중 값이라 릴레이션이 성립하지 않는다.
02 관계형 데이터베이스 모델의 용어
관계형 데이터베이스 모델의 수학적 이론
- 데이터 구조의 테이블에 해당하는 수학의 집합론의 릴레이션을 이론적 토대로 사용한다.
장점 : 개념과 규칙을 수학 언어로 엄밀하게 정의하는 것이 가능하다.
단점 : 추상화되어 이해하기 어려워졌다.
릴레이션
- 수학의 집합론에서 사용하는 테이블에 해당하는 자료형의 명칭이다.
- 하나의 릴레이션은 구조 정보인 스키마(schema)와 데이터 정보인 인스턴스(instance)로 구성된다.

03 무결성 제약조건
- 슈퍼키 : 하나의 릴레이션을 구성하는 속성들 중에서 각 튜플을 유일하게 식별할 수 있는 속성들의 집합이다. (유일성)
-> 유일하게 식별만 하면 되므로, 불필요한 속성이 포함될 수도 있다.
- 후보키 : 슈퍼키 중에서 최소한의 속성들로만 구성된 키 (유일성 + 최소성)
-> 하나의 릴레이션에는 여러 개의 후보키가 존재할 수도 있다.
- 기본키 : 여러 후보키 중에서 하나를 대표로 선택한 키이다.
-> 튜플을 식별하는 기준으로 사용된다.
- 대체키 : 기본키로 선정되지 않은 나머지 후보키이다.
- 외래키 : 다른 릴레이션의 기본키를 참조하는 속성 또는 속성의 집합이다.
-> 다른 릴레이션의 기본키를 참고해서 관계 데이터 모델의 특징인 릴레이션들 간의 관계를 표현한다.
-> 외래키 속성은 참조하는 릴레이션의 기본키와 동일한 도메인을 가져야 한다.
1. 다른 릴레이션을 참조하는 외래키

2. 자체 릴레이션을 참조하는 외래키

3. 기본키 구성요소가 되는 외래키

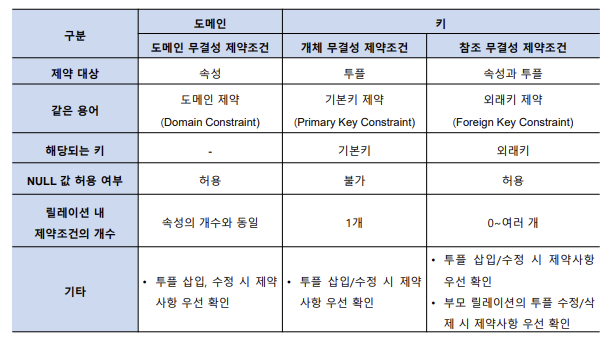
- 데이터 무결성 : 데이터베이스에 저장된 데이터의 일관성과 정확성을 지키는 것이다.
- 도메인 무결성 제약조건 : 도메인 제약이라고도 하며 릴레이션 내의 튜플들이 각 속성의 도메인에 지정된 값만 가져야 한다.
- 개체 무결성 제약조건 : 기본키 제약이라고도 하며 릴레이션의 기본키는 NULL 값을 가져서는 안 되며 릴레이션 내에 오직 하나의 값만 존재해야 한다.
- 참조 무결성 제약조건 : 외래키 제약이라고도 하며 릴레이션 간의 참조 관계를 선언하는 제약조건이다.
-> 자식 릴레이션의 외래키는 부모 릴레이션의 기본키와 도메인이 동일해야 하고, 자식 릴레이션 값이 변경될 때는 부모 릴레이션의 제약을 받는다.
개체 무결성 제약조건
- 삽입 : 기본키 값이 같으면 삽입이 금지된다.
- 수정 : 기본키 값이 같거나 NULL로도 수정이 금지된다.
- 삭제 : 특별한 확인이 필요하지 않다.

참조 무결성 제약조건
- 삽입
* 학과 (부모 릴레이션) : 튜플 삽입 후 수행하면 정상적으로 진행된다.
* 학생 (자식 릴레이션) : 참조받는 테이블에 외래키가 없으므로 삽입이 금지된다.

- 삭제
* 학과 (부모 릴레이션) : 참조하는 테이블을 같이 삭제할 수 있어서 금지하거나 다른 추가 작업이 필요하다.
* 학생 (자식 릴레이션) : 바로 삭제가 가능하다.
- 수정
* 삭제와 삽입 명령이 연속해서 수행된다.
* 부모 릴레이션의 수정이 일어날 경우 삭제 옵션에 따라 처리된 후 문제가 업으면 다시 삽입 제약조건에 따라 처리된다.


'Major Study > 25-1 Database' 카테고리의 다른 글
| [Database] 06 데이터입력 SQL (3) | 2025.04.18 |
|---|---|
| [Database] 05 관계형 데이터 모델 (0) | 2025.04.17 |
| [Database] 03 데이터베이스 설계 (0) | 2025.04.17 |
| [Database] 02 데이터 수집과 구조 (3) | 2025.04.09 |
| [Database] 01 데이터베이스 시스템 (2) | 2025.04.08 |



