import pandas as pd
wine = pd.read_csv('https://bit.ly/wine_csv_data')
wine.head()
네 번째 열 class는 타깃값으로 0이면 레드 와인, 1이면 화이트와인이다.
화이트와인이 양성 클래스이고 데이터에서 화이트와인을 골라내는 문제를 다룬다.
wine.describe()

describe()를 사용해서 통계값을 보면, 도수, 당도, pH 값의 스케일이 다르다.
# 넘파이 배열로 변환
data = wine[['alchool','sugar','pH']].to_numpy()
target = wine[['class']].to_numpy()
# 훈련 세트와 테스트 세트로 나누기
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
# 데이터 전처리
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
>>> 0.7808350971714451
>>> 0.7776923076923077
결정 트리
의사결정 트리는 분류(classification)와 회귀(Regression)를 위한 비모수적인 지도 학습 방법이다.
데이터의 특징(feature)으로부터 유추된 단순한 if-then-else 규칙으로 목표 변수 (target variable)를 예측한다.
트리는 구간별 상수 함수(piecewise constant function)로 보며, 트리의 깊이가 깊을 수록 복잡하고 정밀한 예측이 가능하다.
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_tagret))
>>> 0.996921300750433
>>> 0.8592307692307692
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
루트 노드 (Root Node)는 트리의 맨 위에 위치한 첫 번째 노드이다.
전체 데이터에서 가장 중요한 기준 (feature)을 사용하여 처음 분할을 수행한다.
내부 노드(Internal Node / Decision Node)는 데이터를 특정 기준인 feature와 임계값에 따라 둘 이상으로 나누는 노드이다.
각각의 내부 노드에서 if-then-else 조건문을 포함하고 있다.
잎 노드(Leaf Node / Terminal Node)는 더 이상 분할되지 않는 최종 노드로 실제 예측값이다.
각 잎 노드는 그 노드에 도달한 데이터 샘플들의 결과를 대표한다.
분류 문제에서는 클래스 라벨, 회귀 문제에서는 평균값이 주어진다.
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alchool','sugar','pH'])
plt.show()
max_depth 매개변수를 1로 주면 루트 노드를 제외하고 하나의 노드를 더 확장하여 그린다.
filled 매개변수는 클래스에 맞게 노드에 색을 입힌다.
feature_names 매개변수는 특성의 이름을 전달한다.
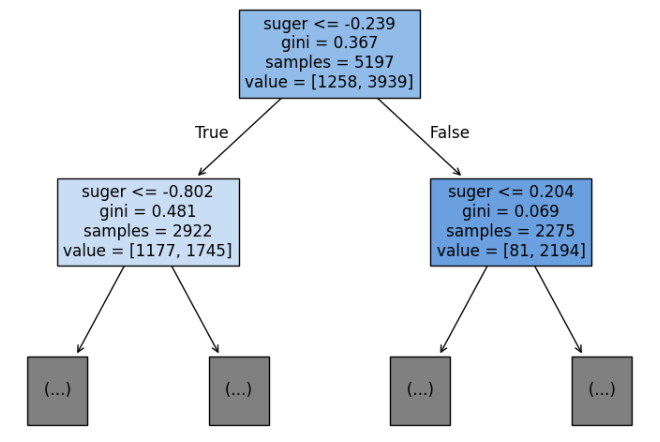
불순도
gini는 지니 불순도(Gini impurity)를 의미한다.
DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값이 gini이다.
criterion 매개변수는 노드에서 데이터를 분할할 기준을 정하는 것이다.
지니 불순도 = 1 - (음성 클래스 비율^2 + 양성 클래스 비율^2)
결정 트리 모델은 부모 노드와 자식 노드의 불순도 차이(정보 이득)가 가능한 크도록 트리를 성장시킨다.
정보 이득 = 부모의 불순도 - (왼쪽 노드 샘플 수 / 부모의 샘플 수) x 왼쪽 노드 불순도 - (오른쪽 노드 샘플 수 / 부모의 샘플 수) x 오른쪽 노드 불순도

p는 노드 내에서 클래스 i의 비율이다.
모든 요소가 하나의 클래스에만 속하면 지니 값은 0이다.
즉, 지니 값은 높을 수록 클래스가 섞여 있는 것이다.
일반적으로 CART (분류 혹은 회귀 트리) 에서 사용된다.
또한 엔트로피는 로그 계산이 필요하지만 지니 지수는 로그를 사용하지 않기 때문에 계산이 빠르다.
가지치기
결정트리에서 가지치기는 자라날 수 있는 트리의 최대 깊이를 지정하는 것이다.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
>>> 0.8454877814123533
>>> 0.8415384615384616
훈련 세트의 성능은 낮아졌지만 테스트 성능은 그대로다.
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alchool','suger','pH'])
plt.show()
결정 트리는 어떤 특성이 가장 유용한지 나타내는 특성 중요도를 계산할 수 있다.
이 트리의 루트 노드와 깊이 1에서 당도를 사용했기 때문에 아마도 당도(sugar)가 가장 유용한 특성일 것이다.
print(dt.feature_importances_)
>>> [0.12345626 0.86862934 0.0079144 ]
두 번째 특성인 당도가 0.87 정도로 가장 높다.
위 세 가지 값을 더하면 1이 된다.
특성 중요도는 각 노드의 정보 이득과 전체 샘플에 대한 비율을 곱한 후 특성별로 더하여 계산한다.
이 특성 중요도로 결정 트리 모델의 특성 선택에 활용할 수 있다는 장점이 있다.
'Major Study > 25-1 Machine Learning' 카테고리의 다른 글
| [Machine Learning] chapter4 - 로지스틱 회귀 (0) | 2025.04.30 |
|---|---|
| [Machine Learning] chapter3 - 회귀 알고리즘과 모델 규제 (0) | 2025.04.11 |
| [Machine Learning] chapter 2 - 데이터 다루기 (0) | 2025.04.01 |
| [Machine Learning] chapter 1 - 머신러닝 (0) | 2025.04.01 |



